
[UPDATE 2022-11-25]: Trustpilot has changed their DOM, which means that this script will no longer work. You might be able to solve it by replacing some of the scraping attributes, but I have not had time to update the code myself.
First of all, I have to give a huge load of credit to Fredrik Cederlöf, who published a script for scraping Trustpilot that inspired me to write my own version that could scrape all relevant attributes for the reviews. If you're only interested in downloading the data you could simply install my library instead of recreating the code.
devtools::install_github("lynuhs/TrustpilotR")
library(TrustpilotR)
trustpilotData <- trustpilot("domain.com")
Just a little heads up, some of the following lines of code will look a bit "crapy" in lack of a better term. If you have a better solution for getting the same results then please share your ideas in the comment section below.
For the actual extraction from Trustpilot we are only going to need the Rvest library, but for visualisation purposes we will also import GGplot2.
library(rvest)
library(ggplot2)
trim <- function(str){
gsub("^\\s+|\\s+$", "", str)
}
factorToCharacter <- function(df){
for (i in 1:ncol(df)){
if(is.factor(df[,i])){
df[,i] <- as.character(df[,i])
}
}
return(df)
}
The two functions in the above code are sort of cleaning functions. The first one will trim a string in order to remove white space. The second will change all factor columns to character.
The next part is not necessary at all. It is a function that creates a customized theme that can be used with GGplot.
library(rvest)
library(ggplot2)
trim <- function(str){
gsub("^\\s+|\\s+$", "", str)
}
factorToCharacter <- function(df){
for (i in 1:ncol(df)){
if(is.factor(df[,i])){
df[,i] <- as.character(df[,i])
}
}
return(df)
}
The scraping of Trustpilot will be put inside a function that will use only one single variable; the domain that you want to scrape the review for.
trustpilot <- function(domain){...}
Let's dive into what the function will do!
url <- paste0("https://www.trustpilot.com/review/", domain, "?languages=all")
We will start by defining the base URL for the specified domain. Notice that we add "?languages=all" to include all reviews. The thing is that Trustpilot will only show 20 reviews on the same page which means we need to walk through all sub pages. To know how many pages we need to walk through we first import information about the total number of reviews.
totalReviews <- read_html(url) %>%
html_node(".headline__review-count") %>%
html_text()
totalReviews <- as.integer(gsub(",","", totalReviews))
reviews <- NULL
cat("\014")
cat(paste0("The script will run on ", ceiling(totalReviews/20), " pages!\n"))
Sys.sleep(2)
We also create an empty variable called 'reviews'. This will later be populated with the actual review data. The last part in the code above will clear the console and print out how many pages will be walked through. We now need to create a loop for all the pages.
for (i in 1:ceiling(totalReviews/20)){...}
In this for loop we will do all the scraping. Let's go through it piece by piece.
page <- read_html(paste0( url, "&page=", i ))
First we apply the URL for the specific page we want to extract data from.
review_card <- page %>%
html_nodes(".review-card")
Store the code related to each single review card in the variable 'review_card'. If the domain have more than 20 reviews this variable should contain a list of length 20 on the first run. We will use this variable to extract the relevant attributes.
name <- review_card %>%
html_nodes(".consumer-information__name") %>%
html_text() %>%
trim()
First off we extract all the names on the review cards. Notice the last line where we call the trim function we created before.
image <- review_card %>%
html_node(".consumer-information__picture") %>%
html_attr("consumer-image-url")
image[which(regexpr("https", image) < 0)] <- paste0("https:", image[which(regexpr("https", image) < 0)])
Here we import the image URL for the user. This might not be something you need. The last line will apply the correct URL for Trustpilot's default image when the user doesn't have a profile picture.
reviewCount <- review_card %>%
html_nodes(".consumer-information__review-count") %>%
html_text() %>%
trim()
reviewCount <- as.integer(gsub(" review","",gsub(" reviews","",as.character(reviewCount))))
Here we gather information about how many reviews the user has written on Trustpilot. This is definitely something you want to extract. Users who have written more than one review might be more "trustworthy".
rating <- review_card %>%
html_node(".star-rating") %>%
html_attr("class")
rating <- as.integer(gsub("[^[:digit:].,]", "",rating))
Here we read the classes for the reviews and keep only the digits in the text. Trustpilot uses classes with a number in it for the displayed stars. This means that we will get the review in an integer with the above code.
published <- html_text(review_card)
published <- as.Date(substr(published,
unlist(gregexpr("publishedDate.*upda", published, perl=TRUE))+16,
unlist(gregexpr("publishedDate.*upda", published, perl=TRUE))+25))
This code will extract the publish dates for the reviews. I couldn't find a good function to extract the date data where it worked on all of the runs. This does work but it might not be the best looking code. It reads all text in the review card, looks for the text "publishedDate" followed by "upda". Then it gets the substring of the index where it finds the text plus 16 characters ahead (where the date is written).
respondDate <- review_card %>%
html_node(".ndate") %>%
html_attr("date") %>%
substr(1,10) %>%
as.Date()
The dates of replies are easier to extract. It will return NA if a reply does not exist for a specific review.
verified <- review_card %>%
html_node(".review-content-header__review-verified") %>%
html_text()
verified <- regexpr("isVerified", verified) > 0
This is my favorite part. It extracts TRUE or FALSE if the user has verified an order. Reviews from users with verified orders might be more truthful. The code will extract the text in a specific block and then check if the text contains "isVerified".
title <- review_card %>%
html_nodes(".review-content__title") %>%
html_text() %>%
trim()
Here we extract the title of the review card.
content <- review_card %>%
html_nodes(".review-content__text") %>%
html_text() %>%
trim()
With this code we get the content of the review (the actual review).
haveReply <- html_children(review_card) %>%
html_text()
haveReply <- unlist(gregexpr("Reply from", haveReply, perl=TRUE)) > 0
This code will check if the review has been replied by the company. This will later be used in a loop to apply the replies to the correct reviews. We need to do it this way since the list of replies might be shorter than the list of reviews.
reply <- review_card %>%
html_nodes(".brand-company-reply__content") %>%
html_text() %>%
trim()
Here we get the list of all replies on the page.
replies <- NULL
k <- 1
for(j in 1:(length(name))){
if (haveReply[j]){
replies <- c(replies, reply[k])
k <- k+1
} else {
replies <- c(replies, NA)
}
}
This is the loop that was mentioned above. Here we match the replies with the reviews and store them in a new variable called 'replies'. If a review doesn't contain a reply then the variable will contain NA.
reviews <- rbind(reviews, data.frame( name = name, image = image, reviewCount = reviewCount, rating = rating, publishedDate = published, respondDate = respondDate, verifiedOrder = verified, title = title, content = content, reply = replies ))
Here we create a data frame from all the attributes we extracted and then bind them together with the previous extracted data (with the NULL variable the first time we run the loop). We then finish off the loop by printing out what page was just scraped.
print(paste0(url, "&page=", i, " has been scraped"))
Before ending the function we will convert all factor columns to character and also add a column containing the number of characters in the review.
reviews <- factorToCharacter(reviews) reviews$contentLength <- nchar(reviews$content) return(reviews)
To use the function simply type the following line with your own preferred domain name.
hak <- trustpilot("huntakiller.com")
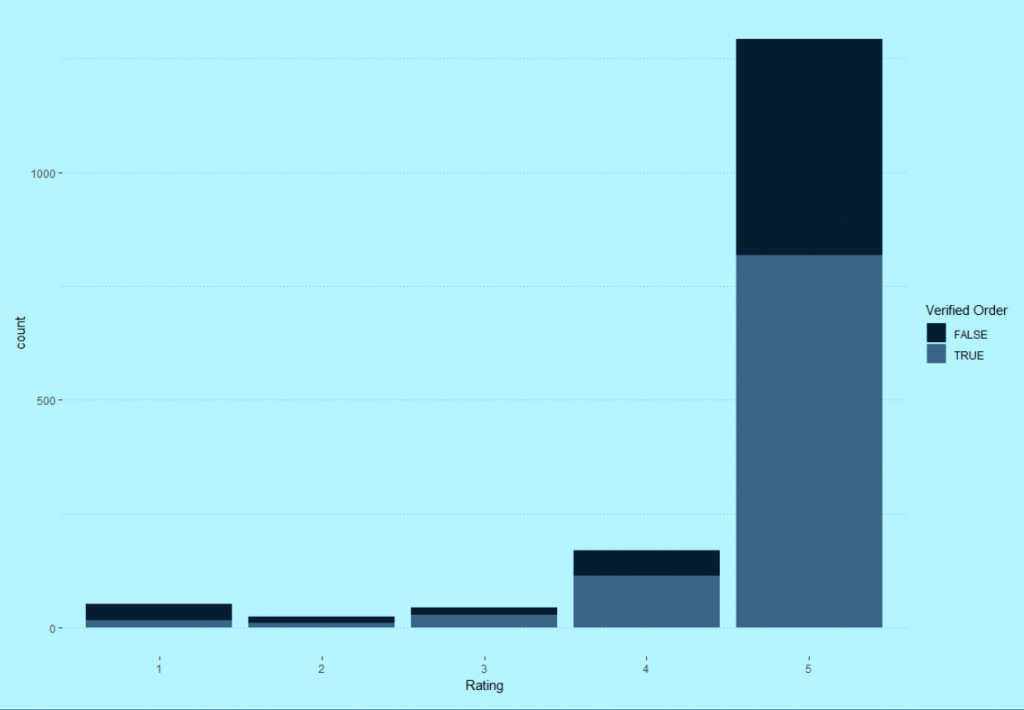
You can now use GGplot to visualize the data from Trustpilot. In this example I have printed out the count of ratings by rating and filled the bars with information if the order has been verified or not.
ggplot(subset(hak, rating > 0), aes(x=as.factor(rating), fill=verifiedOrder)) +
geom_bar(stat="count") +
xlab("Rating") +
labs(fill = "Verified Order") +
scale_fill_manual(values = c("#051d30","#3a6587")) +
lynuhs_theme()
I hope this script will be helpful for you and as usual you can find the script in it's full version on GitHub.
Heidi
2022-11-24 20:25
Hello
I really like your code – well done!
I was just testing it out, also using R, but it seems to meet a problem at
for (i in 1:ceiling(totalReviews/20)){…}, where my machine only says “Error in 1:ceiling(totalReviews/20) : NA/NaN argument” – Do you have any idea as to why? TrustPilot still only has 20 reviews per page…
Hope you will answer soon!
Linus Larsson
2022-11-25 16:04
Hi, it appears that Trustpilot has changed their DOM, which means that all selectors in the script are out of date.