
Two of my biggest hobbies are watching movies/series and data. So not a big surprise that I wanted to get all the IMDB data into Google BigQuery. Once you have all the important data in BigQuery, you could easily search for anything you want to, e.g. movies that stars two of your favorite actors, getting the average rating for a TV show over time etc.
So how do you do this? Unfortunately there isn't an official API available from IMDB. One of the closest things we get is OMDB API, but there's not that much information you could gather from it. Luckily, we get some up to date zip files from IMDB on https://datasets.imdbws.com/. These files are updated daily so all you have to do is download them and send the data to Google BigQuery. However, the data has to be cleaned and structured correctly. Since the files are very large, it will be easier to send the data to Google Cloud Storage and then create the BigQuery tables from the Cloud Storage bucket instead.
Importing the data to RStudio and exporting to Google Cloud Storage
The first thing we need to do is to import the packages "httr" and "googleCloudStorageR", and also authorize the connection to Google Cloud Storage.
library(httr) library(googleCloudStorageR) gcs_auth()
The next part is the actual function that we will use to download and then export the data to Google Cloud Storage. Notice the last part, where we upload an actual CSV file instead of uploading a data frame. This is in order to minimize the memory needed. If you want to, you can try to use bqr_upload_data() instead, but I recommend doing it with CSV file.
imdbToBQConnector <- function(fileName, colTypes = NULL){
# Use the parameter fileName to create the correct download URL from IMDB
url <- paste0("https://datasets.imdbws.com/",fileName,".tsv.gz")
# Download the compressed file to the subfolder "data". Make sure this subfolder exists!
filePath <- paste0("data/",gsub("\\.","_",fileName),".tsv.gz")
GET(url, write_disk(filePath, overwrite = TRUE))
# Read the downloaded file. Notice that it's tab separated and that we are identifying NAs.
data <- as.data.frame(
readr::read_tsv(
file = gzfile(filePath), progress = TRUE, na = "\\N", col_types = colTypes, quote = "",
)
)
file.remove(filePath)
# Remove all citation marks from the character columns
for(c in 1:ncol(data)){
if(is.character(data[,c])){
data[,c] <- gsub("\"", "", data[,c])
}
}
# Replace all NA values with empty strings. This make it to null in Google Cloud.
data[is.na(data)] <- ""
# Write a csv file in the data folder
cloudName <- paste0(gsub("\\.","_",fileName),".csv")
write.csv(data, paste0("data/",cloudName), row.names = FALSE, quote = TRUE)
rm(data)
# Upload the csv file to Google Cloud Storage
gcs_upload(file = paste0("data/",cloudName), bucket = bucket_name, name = cloudName)
file.remove(paste0("data/",cloudName))
cat(crayon::red(paste0(fileName, " uploaded successfully to Google Cloud Storage")))
}
Now that we have the funciton in place, all we need to do is run it with the correct file names, and also a string containing the column types.
imdbToBQConnector("name.basics", c("cciicc"))
imdbToBQConnector("title.akas", c("ciccccci"))
imdbToBQConnector("title.basics", c("cccciiinc"))
imdbToBQConnector("title.crew", c("ccc"))
imdbToBQConnector("title.episode", c("ccii"))
imdbToBQConnector("title.principals", c("cicccc"))
imdbToBQConnector("title.ratings", c("cni"))
That's it. Now you have all up to date data from IMDB in your Google Cloud Storage bucket.
Creating the tables in Google BigQuery
I'm assuming that you have some knowledge of Google BigQuery, since you found this article interesting enough to read this far, so I'm not going to explain in details how to do this and probably, you already know how. First off, create a new dataset called "imdb", or anything to your liking. Then create a new table. Make sure it uses the settings as shown below.
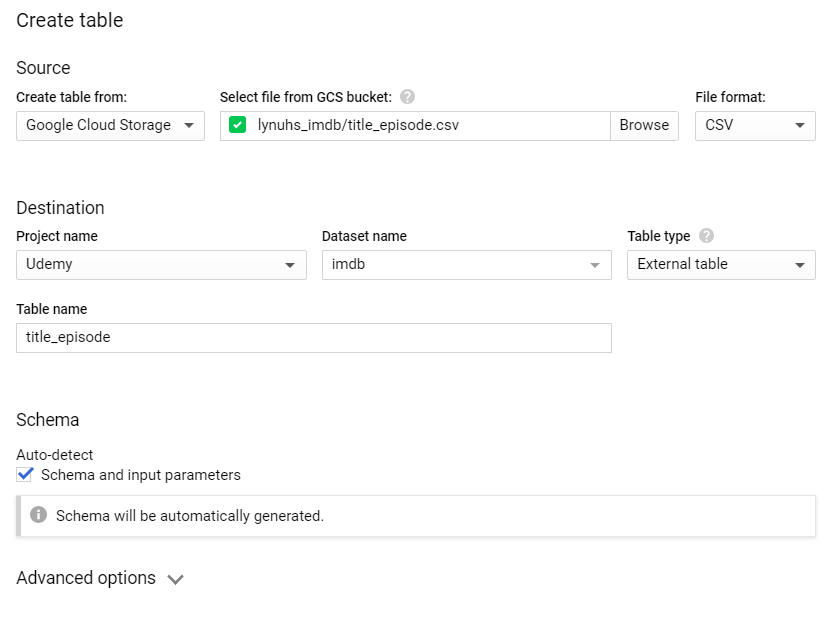
OBS! You might have to type in the column names by yourself for some tables in order to get the correct data type for all columns. If you want your data to be refreshed daily, you could simply put this code in a virtual machine and schedule it to run once a day.
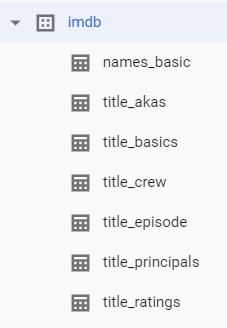
If you followed the steps above, you should have a structure in Google BigQuery that looks like the one below. I hope you found this helpful and if you find any interesting use cases of the data in BigQuery, please comment below.
Comments